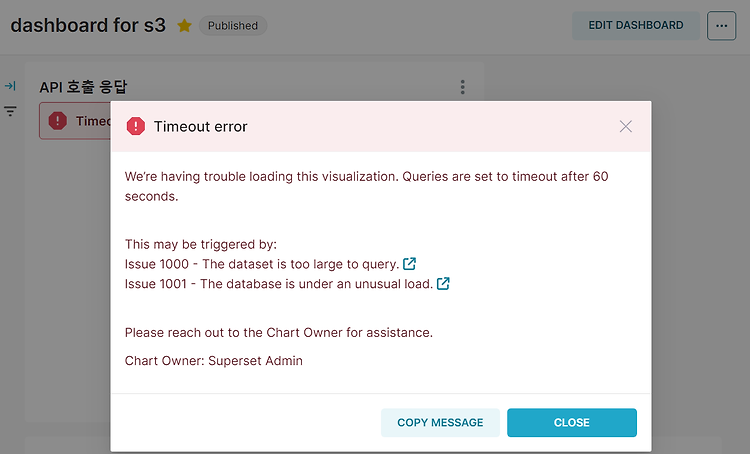
현상 AWS EKS 클러스터에서 Helm으로 Superset을 설치해서 사용하고 있다. 그런데 Superset Dashboard에서 데이터 양이 많은 Chart를 조회하면 60초 정도 로드하다가 Timeout이 발생하면서 실패하는 현상이 발생하고 있다. 원인을 확인하고 현상을 해결해보자. 원인 다행히 비슷한 현상을 겪는 사용자가 많은지 Apache Superset FAQ 문서에 관련 내용이 정리되어 있었다. 공식 문서에 의하면 Superset 서비스 간 통신이 Gateway나 nginx 같은 Proxy 서버를 통해 이뤄지는 경우, 네트워크 서비스 관련 설정으로 인해 대시보드나 차트를 로드하는 중 504 Gateway Time-out과 같은 시간 초과가 발생할 수 있다고 한다. 긴 쿼리를 처리하는 Supe..