개요
2024.03.13 - [Apache Arrow] parquet 파일 읽고 쓰기에서 Python으로 parquet 파일을 읽고 쓰는 방법을 간단히 정리했는데, 데이터를 파티셔닝 해서 저장할 필요가 있어 추가로 정리한다.
파티셔닝
Apache Arrow는 로컬, AWS S3, HDFS 등의 파일 시스템에 파티셔닝 데이터를 읽거나 쓸 수 있다. 기본적으로는 로컬 파일 시스템을 사용한다.
데이터를 쓸 때는 pyarrow.parquet.wrirte_to_dataset 함수에 파일로 저장할 테이블, 파일을 저장할 기본 경로, 그리고 파티셔닝 할 컬럼을 지정한다.
pq.write_to_dataset(table, root_path='dataset_name',
partition_cols=['one', 'two'])
pyarrow.parquet.write_table 함수로는 데이터를 파티셔닝할 수 없는 것 같다.
테스트
iris 데이터세트로 파티셔닝 저장 테스트를 해보자.
import seaborn as sns
df = sns.load_dataset('iris')
table = pa.Table.from_pandas(df)
일반적으로 데이터를 파티셔닝할 때는 시계열 데이터를 많이 사용하는데, iris 데이터 세트에는 시계열 컬럼이 없어서 species 컬럼을 기준으로 파티셔닝을 해보려고 한다. 저장 경로는 현재 python 프로젝트 경로의 iris 디렉터리로 지정한다.
pq.write_to_dataset(table, root_path='iris',
partition_cols=['species'])

코드를 실행하면 iris라는 디렉터리에 '컬럼=값' 형식으로 디렉터리가 생성되고, 각 디렉터리에 parquet 파일이 저장된다. pyarrow.parquet.ParquetDataset.files 속성을 사용하면 parquet 데이터가 저장된 파일 목록을 확인할 수도 있다.
pq.ParquetDataset(path_or_paths='iris').files
실제로 데이터가 정상적으로 파티셔닝되어 있는지도 확인해보려고 했는데,
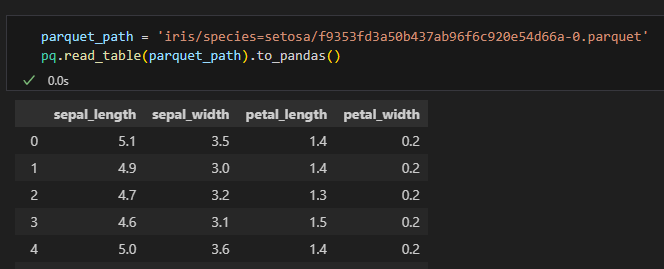
아무래도 파티션 기준 컬럼은 디렉터리를 분할할 때 사용하므로 저장되는 파일 데이터에는 제외하는 것 같다…….
참고 문서
https://arrow.apache.org/docs/python/parquet.html
https://arrow.apache.org/docs/python/generated/pyarrow.parquet.write_to_dataset.html
https://arrow.apache.org/docs/python/generated/pyarrow.parquet.ParquetDataset.html