개요
2024.03.13 - [Apache Arrow] parquet 파일 읽고 쓰기, 2024.03.14 - [Arrow] 파티셔닝한 parquet 파일 저장하기에서 Apache Arrow를 이용해 parquet 데이터를 읽고 쓰는 방법을 적어두었었는데, Pandas를 통해서 parquet 데이터를 읽고 쓸 수도 있다.
이 글에서는 Pandas를 이용한 방법을 적어둔다.
read_parquet
read_parquet 함수는 경로에 저장된 parquet 파일을 읽은 DataFrame을 반환한다.
import pandas as pd
pd.read_parquet('iris.parquet')
단일 파일 하나만 전달하거나, 여러 파일이 파티셔닝되어 저장된 경로를 전달해도 된다.
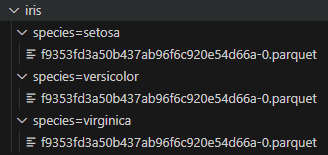
가령 iris란 경로에 parquet 파일이 species라는 컬럼으로 파티셔닝되어 있다면, iris라는 경로를 전달하면 된다.

parquet 파일이 저장된 경로에는 문자열 뿐만 아니라, path 객체, read 함수가 구현되어 있는 file-like 객체, URL을 지정할 수 있다. 또 s3와 같은 클라우드 저장소로도 지정할 수 있다.
to_parquet
to_parquet 함수는 DataFrame을 지정한 경로에 parquet 파일로 작성한다.
import seaborn as sns
df = sns.load_dataset('titanic')
df.to_parquet('titanic.parquet')
만약 파티셔닝을 적용하고 싶다면 partition_cols 매개변수에 파티션 기준 컬럼을 나열하면 된다.
df.to_parquet('titanic', partition_cols=['class'])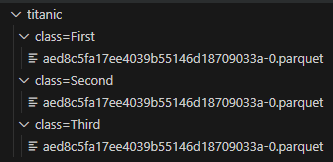
참고 문서
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_parquet.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_parquet.html