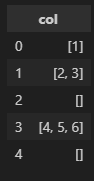
개요 Pandas에서 데이터프레임에 대한 열 필터링을 할 때는 아래와 같은 코드를 사용한다. df[df['column'] == 'value'] 만약 조건이 되는 값이 여럿일 때는 OR 연산자를 사용할 수 있다. df[(df['column'] == 'value1')] | (df['column'] == 'value2')] 하지만 조건이 될 수 있는 값이 보다 많을 때는 OR 연산자를 사용하는 것보다 isin 함수를 사용하는 것이 좋을 것 같다. 사용 방법을 적어둔다. DataFrame.isin isin 함수는 DataFrame의 요소가 값에 포함되어 있는지를 판단한다. 값은 iterable, Series, Dictionary, DataFrame 등으로 지정할 수 있다. 예시 데이터 ) data = {"반" ..