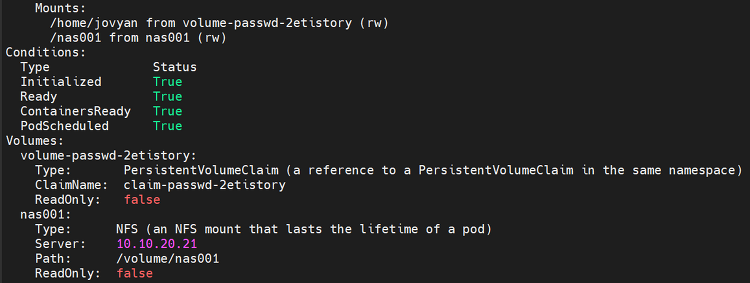
현상 Kubernetes 클러스터에서 top 명령어를 사용할 수 있도록 아래의 명령어로 metrics-server를 설치하였다. kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml 리소스 배포는 정상적으로 완료했으나 여전히 top 명령어를 사용할 수 없는 상태다. 원인 파악하고 문제를 해결해보자. 원인 파악 확인해 보니 metrics-server pod가 정상적인 Running 상태로 전환되지 않고 있었다. kubectl get pods -n kube-system metrics-server metrics-server pod의 이벤트를 확인해보니 readinessPr..