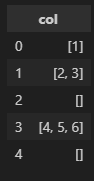
개요 데이터형이 리스트인 컬럼을 데이터프레임이 있다고 하자. 컬럼의 리스트가 비어있지 않은 행만 필터링하고 싶다. 방법을 적어둔다. 예시 데이터프레임 import pandas as pd df = pd.DataFrame({"col": [[1], [2, 3], [], [4, 5, 6], []]}) 이 데이터프레임을 필터링하여 인덱스가 0, 1, 3인 행만 남기려고 한다. 방법 1. str.len으로 리스트 길이 확인 str.len을 활용하면 리스트의 길이를 확인할 수 있다. print(df['col'].str.len()) 이를 이용하여 리스트의 길이가 0이 아닌 행만 필터링한다. df[df['col'].str.len() != 0] 다만 벡터화 연산을 사용한 것이 아니기 때문에 데이터프레임의 크기가 크다면 실..