개요
데이터를 Pandas 데이터프레임으로 처리하려고 하는데, 데이터프레임 행 전체를 순회하면서 처리해야 하는 작업이 발생했다.
데이터프레임 행 순회를 하는 방법을 간단히 정리해 둔다. 물론 데이터프레임의 크기가 클수록 순회하는 것보다 벡터화 연산으로 처리하는 것이 유리하다.
인덱싱
아래와 같은 데이터프레임이 있다고 하자.
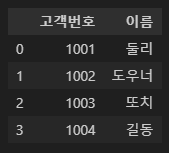
import pandas as pd
df = pd.DataFrame({
'고객번호': [1001, 1002, 1003, 1004],
'이름': ['둘리', '도우너', '또치', '길동']
}, columns=['고객번호', '이름'])데이터프레임의 인덱스 정보는 index 속성으로 접근할 수 있다. for문으로 데이터프레임의 인덱스 정보를 순회하면서 loc, iloc 등을 이용해 접근하면 된다.
print(df.index)
for i in df.index:
print(df.loc[i])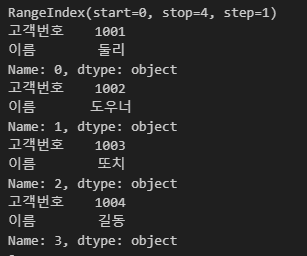
iterrows
iterrows 함수는 데이터프레임의 행을 인덱스와 시리즈의 튜플 형식으로 반환한다.
for i, row in df.iterrows():
print(f'{i}\n{row}')
itertuples
itertuples 함수는 데이터프레임의 행을 namedtuples 형식으로 반환한다.
for row in df.itertuples():
print(row)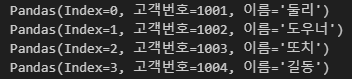
참고 문서
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.iterrows.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.itertuples.html
728x90