개요
어떤 데이터가 처리되던 방식을 변경하려고 한다. 변경된 처리 방식을 적용하기 전에 기존 방식으로 처리된 데이터와 새로운 방식으로 처리된 데이터가 동일한지 확인하고 싶다.
각 방식으로 처리된 DataFrame을 비교하면 될 것 같아, 이 글에서 DataFrame을 비교하는 여러 방법 중 equals 함수 사용법에 대해 정리한다.
DataFrame.equals
equals 함수는 DataFrame 또는 Series를 서로 비교하여 동일한지 확인한다. 만약 NaN이 동일한 위치에 있다면 같은 것으로 취급한다. 두 객체의 모든 요소가 동일하면 True, 그렇지 않으면 False를 반환한다.
테스트
1. 같은 데이터로 생성한 DataFrame 비교
data = {
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
}
df_v1 = pd.DataFrame(data)
df_v2 = pd.DataFrame(data)
df_v1.equals(df_v2)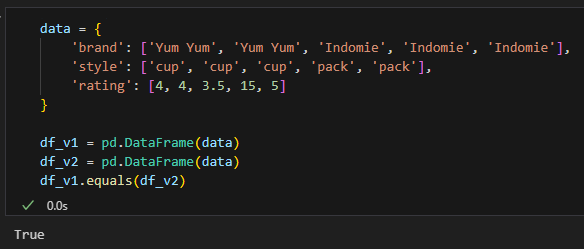
동일한 데이터로 생성했기 때문에 두 DataFrame은 같다.
2. 데이터 내용은 같지만 컬럼 순서가 다른 경우
data = {
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
}
df_v1 = pd.DataFrame(data)
df_v2 = df_v1.reindex(columns=['brand', 'rating', 'style']) # 컬럼 순서 변경
display(df_v2)
print(df_v1.equals(df_v2))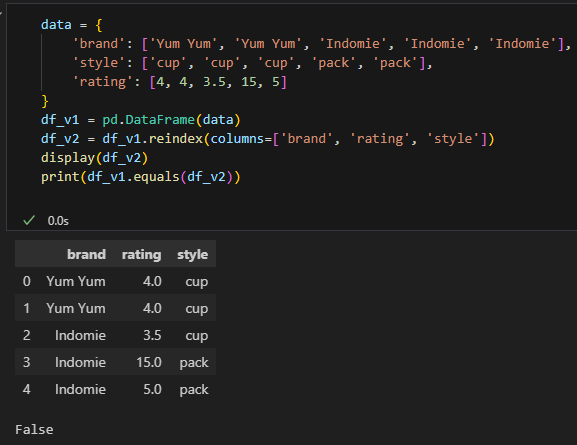
데이터가 같아도 컬럼 순서가 달라지면 같은 데이터프레임이라고 취급하지 않는다.
3. 데이터 내용은 같지만 행 순서가 다른 경우
data = {
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
}
df_v1 = pd.DataFrame(data)
df_v2 = df_v1.reindex(index=df_v1.index.to_list()[::-1]).reset_index(drop=True) # 행 순서 변경
display(df_v2)
print(df_v1.equals(df_v2))
df_v1의 행 순서를 뒤집어서 df_v2를 생성했는데, 두 데이터프레임의 컬럼 순서가 동일해도 행 순서가 일치하지 않으면 역시 다른 데이터프레임이라고 취급하는 모습을 확인했다.
결론
데이터프레임 컬럼 순서 정도야 맞출 수 있으나, 각 데이터 처리 과정에서 데이터 순서가 변경되지 않는다는 보장이 없다면 equals 함수를 활용하기는 조금 어려울 것 같다. 다른 좋은 방법을 더 확인해봐야 할 것 같다.
참고 문서
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.equals.html