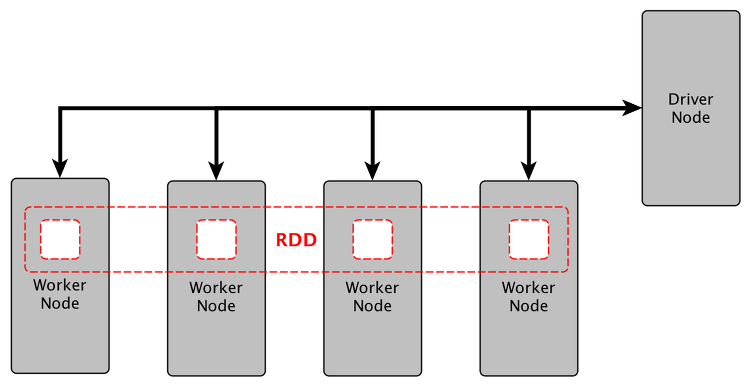
현상 PySpark가 동작하는지 확인하고자 간단히 DataFrame을 생성하는 코드를 실행했다. from pyspark.sql import SparkSession if __name__ == '__main__': # SparkSession 초기화 spark = SparkSession.builder.appName("Simple Application").getOrCreate() # 데이터프레임 생성 data = [("James", "", "Smith", "1991-04-01", "M", 3000), ("Michael", "Rose", "", "2000-05-19", "M", 4000), ("Robert", "", "Williams", "1978-09-05", "M", 4000), ("Maria", "Anne"..