개요
Python에서 boto3을 이용해 S3 버킷에 저장된 객체 목록을 가져올 때는 list_object, list_object_v2 함수를 사용한다. 이 두 함수는 최대 1000개의 객체를 반환한다. 따라서 1000개 이상의 객체가 저장된 prefix에 대해 list_object를 요청해도 모든 객체를 반환받지 못한다.
AWS에서 제공하는 Paginator를 사용해 문제를 해결해 보자.
Paginator 사용
AWS operation 중 전체 결과 집합을 얻기 위해 후속 요청이 필요한 경우, 이전 요청이 중단된 곳에서 작업을 지속하기 위해 후속 요청을 보내는 프로세스를 pagination이라고 한다. Paginator는 API 작업의 전체 결과 집합에 대해 반복하는 프로세스에 대한 추상화 역할을 한다.
Paginator는 다음과 같이 s3 클라이언트 객체에 get_paginator 함수를 호출하여 얻을 수 있다. get_paginator 함수 호출 시에는 작업할 API를 전달한다.
import boto3
client = boto3.client('s3')
paginator = client.get_paginator('list_objects_v2')그리고 paginator의 paginate 함수를 호출하여 응답을 페이지 단위로 저장하는 iterator를 생성한다. paginate 함수에는 작업하는 API에 전달하는 매개변수를 동일하게 전달하면 되는 것 같다.
pages = paginator.paginate(Bucket=bucket, Prefix=prefix)이후 반복문을 이용해 각 page에 접근하여 응답을 얻을 수 있다.
response = list()
for page in pages:
response += page['Contents']
return response
list_object_v2 VS paginator
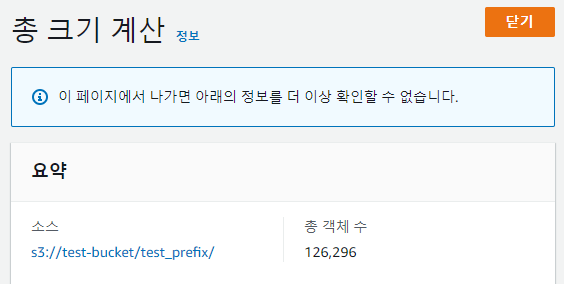
사진의 S3 prefix를 대상으로 list_object_v2 함수와 paginator를 사용했을 때의 결과 차이가 있는지 확인해 본다.
import boto3
client = boto3.client('s3')
bucket = 'test-bucket'
prefix = 'test_prefix'
# list_objects_v2 응답
resp_list_objects = client.list_objects_v2(Bucket=bucket, Prefix=prefix, ).get('Contents', '')
# pagninator 응답
paginator = client.get_paginator('list_objects_v2')
pages = paginator.paginate(Bucket=bucket, Prefix=prefix)
resp_paginator = list()
for page in pages:
resp_paginator += page['Contents']
print(prefix)
print(len(resp_list_objects))
print(len(resp_paginator))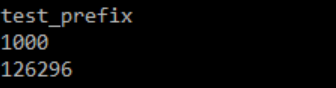
실제로도 응답 수에 차이가 있었고, paginator를 사용한 결과가 aws console에서 사용한 결과와 동일하다는 것을 확인할 수 있다.
참고 문서
https://boto3.amazonaws.com/v1/documentation/api/latest/guide/paginators.html