개요
Spark에 대한 개념만 공부할 뿐만 아니라 직접 코딩을 해볼 수 있도록 Window 10에 환경을 구성해보려고 한다. 최신 버전인 Spark 3.5.0를 설치한다.
설치가 필요한 소프트웨어는 다음과 같다.
- Java 11
- Spark 3.5.0
- Hadoop 3.3 : window 용 바이너리만 설치.
❗❓ Scala는 설치 안 하나요?
Spark는 scala 2.12 / 2.13 버전에서 실행되는데, 이 글에서 설치할 Spark 버전에는 scala가 pre-built 되어 있어 별도 설치가 필요하지 않다.
물론 scala로 코딩을 한다면 설치해야할 것 같지만, 추가로 공부를 해야 하는 입장이라 아무래도 python으로 코딩할 것 같다. 따라서 이 글에서는 설치하지 않는다.
Java 설치
공식 문서 https://spark.apache.org/docs/latest/에 따르면 Spark는 Java 8/11/17, Scala 2.12/2.13, Python 3.8 +, R 3.5+ 에서 실행된다. 이 글에서는 Hadoop을 사용할 수 있는 Java 8/11 중 조금 더 최신인 11을 설치한다.
설치 : https://www.oracle.com/kr/java/technologies/javase/jdk11-archive-downloads.html

참고로 Oracle Java는 다운로드 시 Oracle 계정이 필요하다. 번거롭다면 OpenJDK를 사용해도 좋겠다.
다운로드를 완료했으면 설치 파일을 더블클릭하여 실행하면 된다.

이전에는 환경 변수에 Java 실행 경로를 직접 잡아줘야 했는데, 최근에는 설치 과정에서 자동으로 설정하는 것 같다. CMD 등에서 java 명령어가 정상적으로 실행되는지 확인한다.

Spark 설치
설치 : https://spark.apache.org/downloads.html

설치 링크에 접속해 설치할 Spark 버전과 패키지 타입을 지정한다. 이 글에서는 위와 같이 Spark 3.5에 Hadoop 3.3, Scala 2.12를 사용하도록 지정했다.

다운로드를 완료했다면 원하는 위치에 압축을 해제한다.

Hadoop 설치 (?)
Spark 동작에 Hadoop이 필수적인 것은 아니다. 다만 여러 기능을 Hadoop에 의존하고 있고, 클러스터 모드로 실행하려면 HDFS, S3와 같은 분산 파일 시스템이 필요하다고 한다.
일단, 이 글에서는 Hadoop 동작에 필요한 Window 바이너리 파일만 설치한다.
링크 : https://github.com/cdarlint/winutils

링크를 타고 들어가면 많은 Hadoop 버전이 존재한다. Spark 설치 시 지정한 Hadoop 3 중 최신인 3.3.5를 사용하겠다.

bin 폴더의 winutils.exe만 다운로드하면 된다. 적당한 위치에 두자.

환경 변수 설정
필요한 파일을 전부 다운로드했다면, 시스템에서 사용할 수 있도록 환경 변수를 설정해야 한다.
1. 시스템 환경 변수 편집 이동
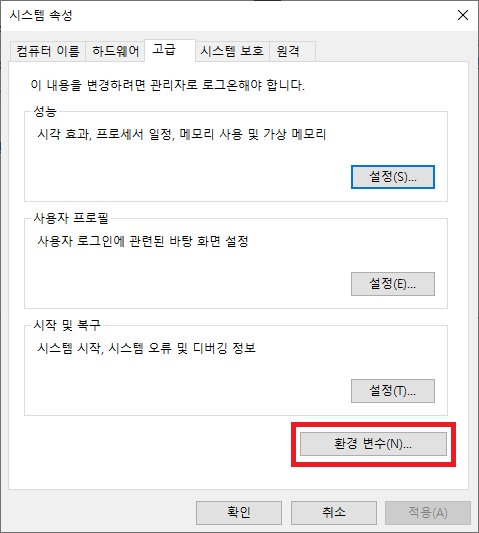
2. 시스템 변수에 SPARK_HOME, HADOOP_HOME 추가
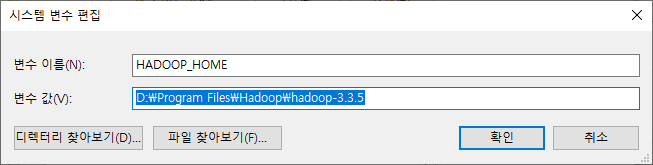
- HADOOP_HOME
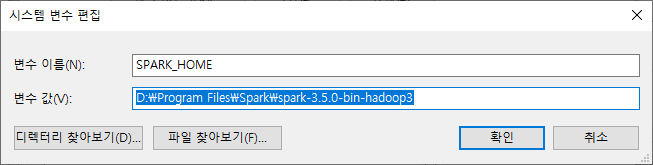
- SPARK_HOME
3. 시스템 변수 Path에 실행 경로 추가
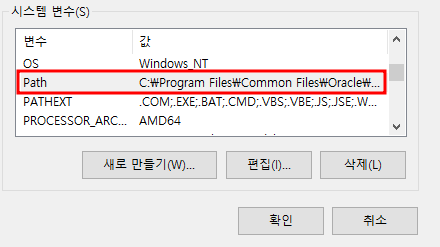
시스템 변수 Path에 Spark, Hadoop 실행을 위한 bin 경로를 추가한다.
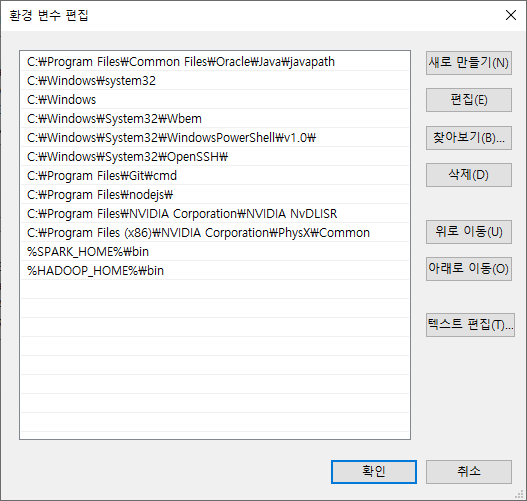
%SPARK_HOME%\bin, %HADOOP_HOME%\bin를 추가했다.
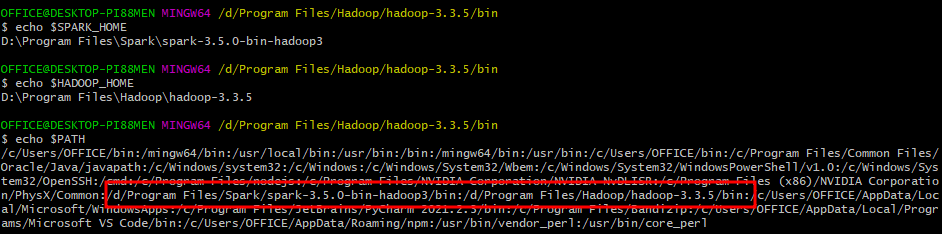
편집한 환경 변수가 정상적으로 설정되었는지 확인한다.
Spark-shell 실행
Spark-shell을 실행하여 Spark가 정상적으로 설치됐는지 확인한다.
spark-shell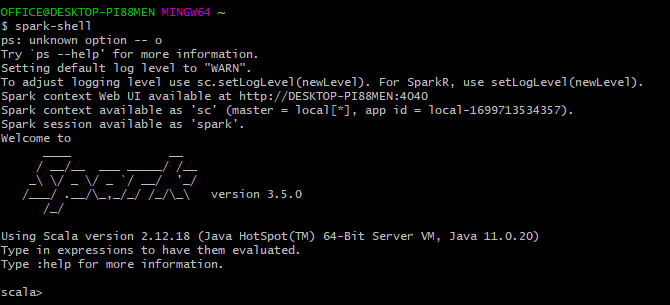
scala를 설치하지 않았지만, scala를 실행할 수 있는 프롬포트가 표시되는 것을 확인할 수 있다.
참고 문서
https://dibrary.tistory.com/89