개요
데이터를 전처리하다 보면 문자열 컬럼을 분할하여 컬럼을 여러 개 추가해야 하는 경우가 많다.
이 글에서는 아래 데이터를 이용해 주소 컬럼을 분할해 도시와 구로 추가하는 방법을 몇 가지 정리한다.
df = pd.DataFrame(
{"이름":["A", "B", "C", "D"],
"나이":["10", "15", "42", "22"],
"주소":["서울;강동구", "인천;연수구", "안양;동안구", "부산;수영구"]}
)
반복문
DataFrame 인덱서를 이용해 반복적으로 셀에 접근하여 데이터를 처리하는 방식이다.
for i in df.index:
df[['도시', '구']] = df.loc[i, '주소'].split(';')데이터양이 적을 때는 사용해도 괜찮지만, 반복문으로 처리하기 때문에 데이터양이 많아질수록 처리 속도가 느리다.
벡터화 연산 - 1
열(Series)에 대해 문자열 처리를 하기 위해 Series.str 함수를 이용하여 split한다. 구분자로 분리된 문자열 결과도 Series이기 때문에 인덱싱할 때도 마찬가지로 Series.str 함수를 이용해야 한다.
df['도시'] = df['주소'].str.split(';').str[0]
df['구'] = df['주소'].str.split(';').str[1]반복문으로 처리하는 것보다 빠르지만, 분리된 문자열을 순차적으로 여러 컬럼으로 만들 때는 코드 중복으로 보일 수 있다.
벡터화 연산 - 2
split 수행 결과를 리스트로 변환한 뒤 DataFrame으로 생성할 수 있다. 생성한 DataFrame을 기존 DataFrame에 합친다.
df[['도시', '구']] = pd.DataFrame(df['주소'].str.split(';').to_list())
벡터화 연산 - 3
split 수행 시 expand=True 매개변수를 추가하면 문자열을 분리한 결과를 리스트로 변환하는 과정 없이 DataFrame으로 받을 수 있다. 가장 간단한 방법이다.
df[['도시', '구']] = df['주소'].str.split(';', expand=True)
apply 함수
문자열 분리나 별도 처리가 다소 복잡한 경우에는 별개의 사용자 정의 함수를 선언한 뒤 적용하는 것도 방법이다. 비교적 간편하다면 lamda 함수를 사용할 수도 있다.
apply를 각 행에 적용해야 할 때는 axis를 1로 주어야 한다.
axis를 1로 지정했을 때는 result_type 매개변수로 반환 타입을 지정할 수 있는데, expand로 지정하면 DataFrame을 반환받을 수 있다.
- lamda 함수 사용
df[['도시', '구']] = df.apply(lambda row: row['주소'].split(';'), axis=1, result_type='expand')
- 사용자 정의 함수 사용 1
DataFrame을 입력받아 처리하는 예시이다. DataFrame을 입력받는 함수를 선언하면 함수를 apply 할 때 매개변수로 DataFrame을 지정하지 않아도 된다.
def split_val(df):
return df['주소'].split(';')
df.apply(split_val, axis=1, result_type='expand')
- 사용자 정의 함수 사용 2
DataFrame의 열을 입력받아 처리하는 예시다. apply를 적용하는 함수에 인자값을 넘길 때는 lambda함수를 사용해도 되고, args 또는 kwargs 매개변수를 사용해도 된다.
def split_val(val):
return val.split(';')
df[['도시', '구']] = df.apply(lambda row: split_val(row['주소']), axis=1, result_type='expand')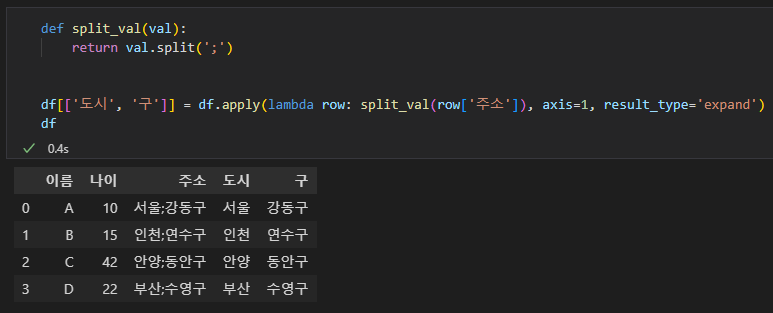
참고 문서
https://suy379.tistory.com/126
https://rfriend.tistory.com/448
https://rfriend.tistory.com/471
https://kibua20.tistory.com/194
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.apply.html