개요
로드해서 처리하고자 하는 데이터 파일이 큰 경우, 메모리가 부족해지는 상황이 발생할 수도 있다. 이런 경우에는 테이터를 읽어오는 시점에서 전체 데이터가 아니라 데이터 조각을 읽어와 처리를 반복하는 것으로 문제 상황을 회피할 수 있다.
이번 글에서는 read_csv를 사용할 때 작은 데이터프레임 단위로 읽는 방법을 적어둔다.
chunksize
Pandas는 csv 뿐만 아니라 여러 형식의 데이터를 로드할 수 있도록 read_json, read_table, read_fwf 등등의 함수를 제공하는데, chunksize라는 매개변수를 전달할 수 있다.
chunksize는 한 번에 읽을 데이터프레임의 행 수를 지정한다. 기본값은 전체 데이터프레임을 로드하는 의미의 None인데, 값이 전달되면 데이터프레임이 아닌 반복을 위한 TextFileReader 객체가 반환된다.
사용 예시
아래와 같이 11개의 행을 가진 CSV 파일이 있다고 하자.
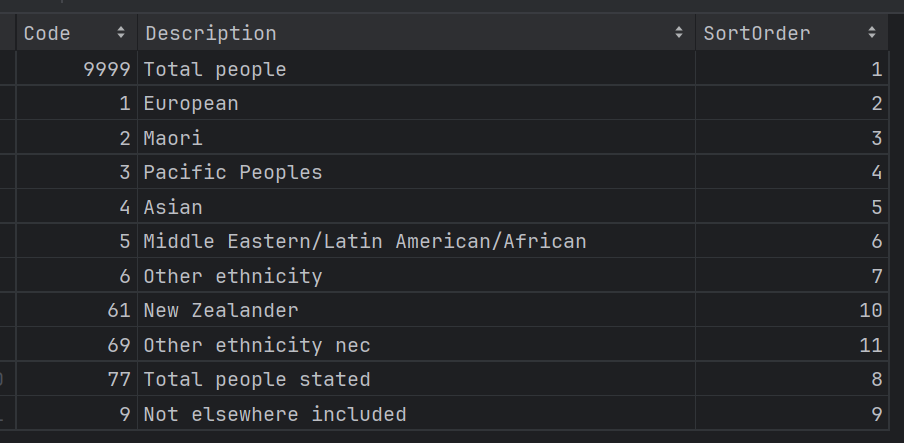
이 데이터를 5개 행만큼 나눠서 로드하려고 할 때는 chunksize에 5를 넣으면 된다.
import pandas as pd
chunks = pd.read_csv('DimenLookupEthnic8317.csv', chunksize=5)
for df in chunks:
print(df)
실행해 보면 5개 행씩 3개 데이터프레임으로 나뉜 것을 확인할 수 있다.
만약 나눴던 데이터프레임을 다시 합치고 싶다면 pd.concat 함수로 붙이면 된다.
import pandas as pd
chunks = pd.read_csv('DimenLookupEthnic8317.csv', chunksize=5)
print(pd.concat(chunks))
참고 문서
pandas로 용량이 큰 csv 파일 읽어오기(kernel dies reading csv file)