개요
2022.12.31 - [Python] Pandas - 피봇테이블과 그룹분석 2에서 그룹 분석을 위한 groupby와 그룹 연산에 대해 정리했다.
이 글에서는 그룹 분석 후 결과 데이터의 인덱스와 컬럼에 대해 적어둔다.
예시 데이터
예시로 사용할 데이터는 아래와 같다.
import pandas as pd
df = pd.DataFrame({
'key1': ['A', 'A', 'B', 'B', 'A'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': [1, 2, 3, 4, 5],
'data2': [10, 20, 30, 40, 50]
})
그룹화 기준 컬럼 처리
groupby 함수로 전달한 그룹화 기준 컬럼은 그룹 연산한 결과의 index가 된다. 결과의 index를 다시 column으로 변환할 때는 reset_index 함수를 사용한다.
df.groupby(['key1', 'key2']).count().reset_index()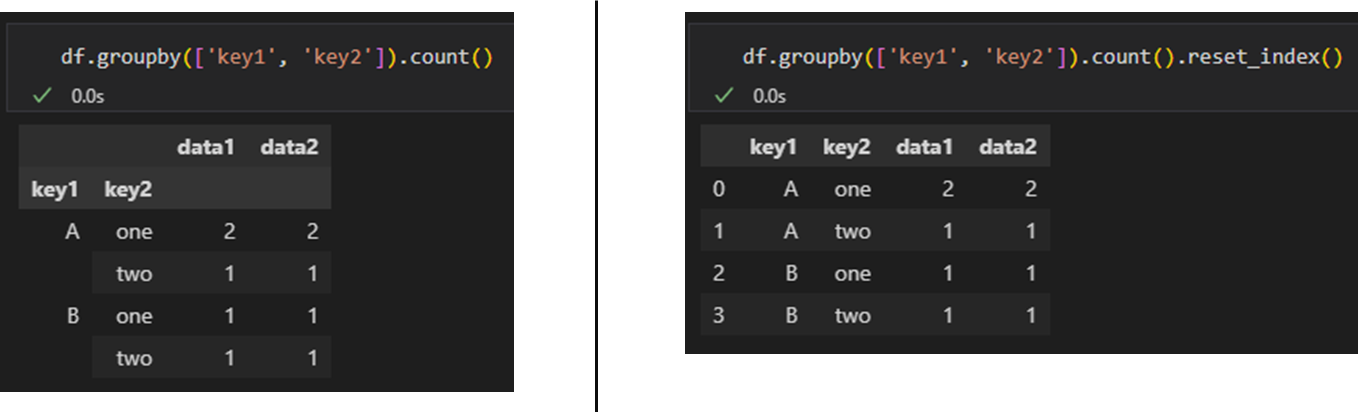
단일 컬럼 이름 변경
만약 하나의 컬럼으로 그룹 연산 후, 컬럼명을 변경하고 싶다면 reset_index 함수 내에 name 매개변수를 전달한다.
df.groupby(['key1', 'key2'])['data1'].count().reset_index(name='cnt1')
이 방법보다는 rename을 사용하는 편이 더 적절해 보이긴 하다.
참고 문서
https://code-code.tistory.com/42
728x90