개요
기존에 처리해서 S3에 저장한 데이터를 새로 처리해 새로운 경로에 저장하고 있다.
예로 들어 기존 데이터가 저장된 S3 경로가 아래와 같다면,
s3://test-bucket/summary/titanic/class=First/27b3ce6245b44ff0950e98419089e66c-0.parquet'
s3://test-bucket/summary/titanic/class=Second/27b3ce6245b44ff0950e98419089e66c-0.parquet'
s3://test-bucket/summary/titanic/class=Third/27b3ce6245b44ff0950e98419089e66c-0.parquet'
s3://test-bucket/raw/iris/species=setosa/2770df01aff1402db5b4de55d1be2a57-0.parquet'
s3://test-bucket/raw/iris/species=versicolor/2770df01aff1402db5b4de55d1be2a57-0.parquet'
s3://test-bucket/raw/iris/species=virginica/2770df01aff1402db5b4de55d1be2a57-0.parquet'새로 처리한 데이터는 다음과 같이 저장한다.
s3://test-bucket/summary_v2/titanic/class=First/27b3ce6245b44ff0950e98419089e66c-0.parquet'
s3://test-bucket/summary_v2/titanic/class=Second/27b3ce6245b44ff0950e98419089e66c-0.parquet',
s3://test-bucket/summary_v2/titanic/class=Third/27b3ce6245b44ff0950e98419089e66c-0.parquet'
s3://test-bucket/raw_v2/iris/species=setosa/2770df01aff1402db5b4de55d1be2a57-0.parquet'
s3://test-bucket/raw_v2/iris/species=versicolor/2770df01aff1402db5b4de55d1be2a57-0.parquet'
s3://test-bucket/raw_v2/iris/species=virginica/2770df01aff1402db5b4de55d1be2a57-0.parquet'이 때 데이터 처리 누락 여부를 확인하기 위해 Pandas를 이용하여 기존 경로를 기반으로 신규 경로를 생성하여 각 객체가 존재하는지 확인하려고 한다. 즉, summary라는 문자열은 summary_v2라는 문자열로 치환하고, raw라는 문자열은 raw_v2라는 문자열로 치환하고자 한다.
단, 최상위 prefix에 해당하는 문자열은 정해져 있지 않다. 따라서 최상위 prefix는 top_prefix라는 이름의 컬럼에 기존 경로를 split한 값으로 저장해두었다.
이 상태에서 기존 경로의 top_prefix를 어떻게 치환할 수 있을까? 방법을 정리해둔다.
예시 데이터
개요에서 예로 든 데이터프레임은 다음과 같다. 기존 경로는 obj_key라는 컬럼으로, 최상위 prefix는 top_prefix라는 컬럼에 저장된 상태이다.
data = ['s3://test-bucket/summary/titanic/class=First/27b3ce6245b44ff0950e98419089e66c-0.parquet',
's3://test-bucket/summary/titanic/class=Second/27b3ce6245b44ff0950e98419089e66c-0.parquet',
's3://test-bucket/summary/titanic/class=Third/27b3ce6245b44ff0950e98419089e66c-0.parquet',
's3://test-bucket/raw/iris/species=setosa/2770df01aff1402db5b4de55d1be2a57-0.parquet',
's3://test-bucket/raw/iris/species=versicolor/2770df01aff1402db5b4de55d1be2a57-0.parquet',
's3://test-bucket/raw/iris/species=virginica/2770df01aff1402db5b4de55d1be2a57-0.parquet']
column = ['obj_key']
df = pd.DataFrame(data, columns=column)
df['top_prefix'] = df['obj_key'].str.split('/').str[3]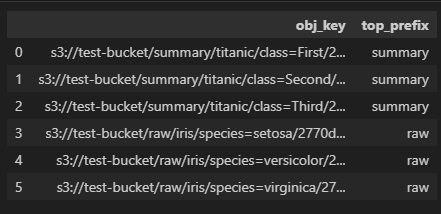
apply 사용
행 별로 문자열 치환이 이루어져야 하므로 apply 함수를 사용하는 방법을 생각해볼 수 있다.
df['obj_key_v2'] = df.apply(lambda row: row['obj_key'].replace(row['top_prefix'], f'{row["top_prefix"]}_v2'), axis=1)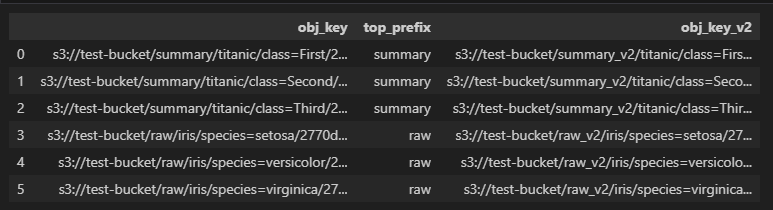
리스트 컴프리헨션 사용
두 컬럼을 Numpy ndarray로 변환한 뒤 리스트 컴프리헨션을 사용해 치환된 문자열 리스트를 생성해 신규 컬럼으로 추가한다.
df['obj_key_v2'] = [x.replace(y, f'{y}_v2') for x, y in df[['obj_key', 'top_prefix']].to_numpy()]
참고 문서
Pandas Dataframe replace part of string with value from another column
728x90