개요
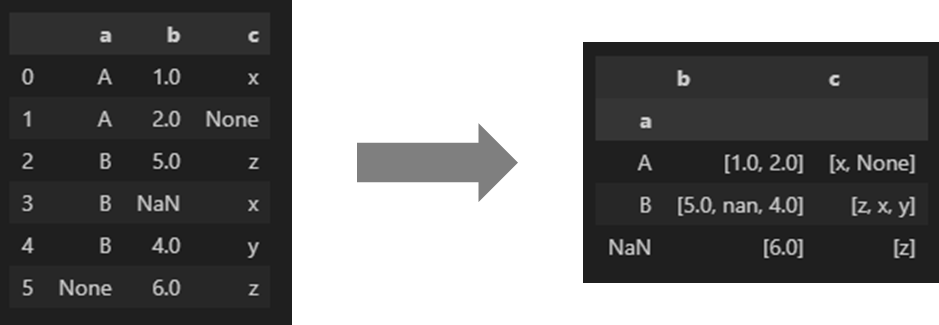
데이터프레임에 대한 그룹 분석이 필요한데, 그룹 별 데이터 값 유지가 필요한 상황이다. 그래서 그룹 연산을 하면서 컬럼을 리스트 형태로 변환하려고 한다.
방법을 적어둔다.
groupby.agg
2022.12.31 - [Python] Pandas - 피봇테이블과 그룹분석 2에서 살펴봤던 사용자 정의 함수로 그룹 분석을 수행하는 agg 함수를 활용하면 된다.
df.groupby('a').agg(list)agg 함수에 list를 넘겨주면 아래와 같이 컬럼 별로 데이터가 리스트 형태로 변환되는 것을 확인할 수 있다.

다만 그룹화하는 기준인 a 컬럼에 결측값이 포함되어 있는데, groupby를 수행하면서 해당 데이터가 누락되는 것을 확인할 수 있다. 이런 경우에는 groupby 함수에 dropna 매개변수로 False로 지정하면 된다.
df.groupby('a', dropna=False).agg(list)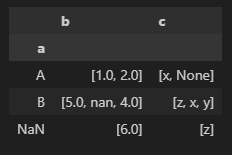
참고로 다른 그룹연산도 함께 적용할 때는 아래와 같이 리스트로 전달한다. list는 문자열로 전달하면 오류를 발생하니 주의해야 한다.
df.groupby('a', dropna=False).agg([list, 'count', 'size'])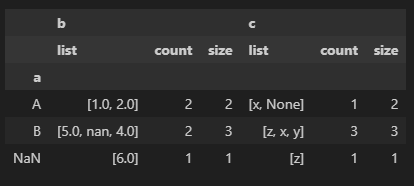
다만 groupby 함수는 성능이 좋은 편은 아니다.
pivot_table
사실 groupby를 이용한 방법보다는 피봇 테이블을 이용하는 편이 보다 보편적인 방법이다.
pt = pd.pivot_table(data=df,
values=['b', 'c'],
index='a',
aggfunc=list)
groupby를 사용할 때와 마찬가지로 list화 외에 여러 연산을 사용하고 싶을 때는 aggfunc 매개변수에 리스트 등으로 사용할 연산을 전달한다.
pt = pd.pivot_table(data=df,
values=['b', 'c'],
index='a',
aggfunc=[list, 'count', 'size'])
다만 pivot_table는 groupby와 달리 NaN을 인덱스로 허용하지 않는다. (일반적으로 결측치는 식별성이 없기 때문에 인덱스로 사용하는 것은 권장되지 않는다.) 즉, 인덱스로 사용할 컬럼에 결측치가 포함되어 있으면 사전에 처리한 후 사용해야 하는 것 같다.
참고 문서
https://stackoverflow.com/questions/22219004/how-to-group-dataframe-rows-into-list-in-pandas-groupby
https://stackoverflow.com/questions/46305536/pandas-pd-pivot-table-with-nan-index