AWS Athena

표준 SQL을 사용해 AWS S3에 저장된 데이터를 분석할 수 있는 대화형 쿼리 서비스
S3에 저장된 데이터를 지정하고 표준 SQL을 사용하면 임시 쿼리를 실행하여 결과를 얻을 수 있다. 즉, S3에 저장된 데이터를 DB에 저장된 데이터처럼 다룰 수 있다.
주로 로그와 같은 대규모 데이터를 로드하고 압축을 푸는데 필요한 시간과 비용을 줄이기 위해 사용한다.
특징
- Serverless
서비스를 이용하기 위해 관리할 인프라가 없다. 또한 AWS 콘솔을 통해 사용할 수 있다. - 비용
실행한 쿼리에 대한 비용을 지불한다. 조금 더 정확하게는 실행한 쿼리가 스캔한 데이터의 용량만큼 비용이 청구되는데 1TB 당 5달러 정도이다. 따라서 데이터 압축이나 파티셔닝을 이용해 스캔하는 양을 줄이면 보다 효율적으로 사용할 수 있으며, DDL과 실패한 쿼리에 대한 비용은 청구되지 않는다.
구성
Facebook에서 개발한 오픈소스 인메모리 분산 쿼리 엔진인 Presto를 AWS에 구현한 것으로, Presto/Trino를 사용한 경험이 있으면 어렵지 않게 사용할 수 있을 것 같다.
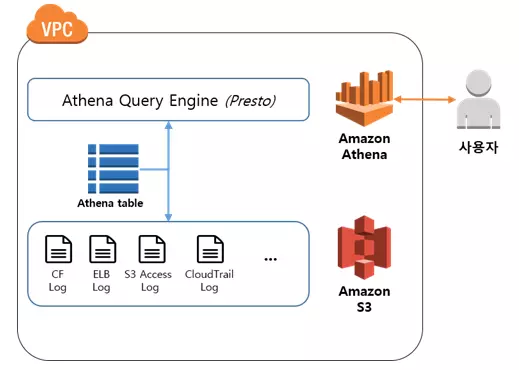
데이터베이스 및 테이블 생성
S3에 저장된 데이터를 SELECT 해보자. 공식 자습서 내용을 기반으로 사용 방법을 정리한다.
1. S3에 쿼리할 데이터 업로드
데이터를 저장하고 있는 S3가 없다면 별도로 생성하여 쿼리 할 데이터를 업로드해야 한다.
S3를 생성하지 않는다면 아래 경로에 저장된 예시 데이터를 사용할 수 있다.
s3://athena-examples-myregion/cloudfront/plaintext/예시 데이터는 AWS ClounFront 로그 데이터로 TSV 형식이다. 경로의 myregion에는 사용하는 AWS 리전을 기재한다.
2. AWS 콘솔에서 Athena > 쿼리 편집기 접근
3. 쿼리 결과 위치 설정
SQL을 실행하기 전에 먼저 Athena로 실행한 쿼리 결과를 저장할 경로를 지정해주어야 한다. 설정 탭 또는 설정 편집 버튼을 클릭한다.
결과를 저장할 위치를 지정한다.
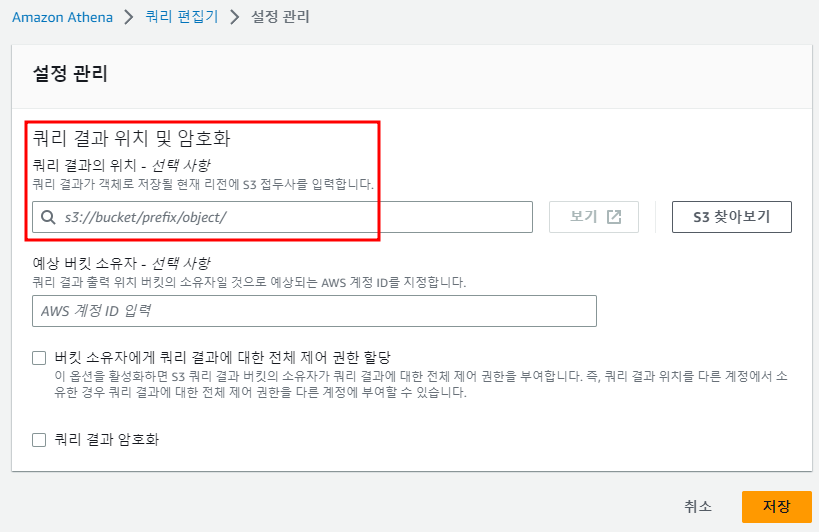
결과 저장 위치를 설정하면 이제 쿼리 편집기에서 SQL문을 사용할 수 있게 된다.
4. 데이터베이스 생성
DB를 다룰 때와 비슷하게 데이터베이스를 생성한다.
CREATE DATABASE <database_name>;
-- 예시
CREATE DATABASE test_athena;
실행하면 데이터베이스가 생성된 것을 확인할 수 있다.
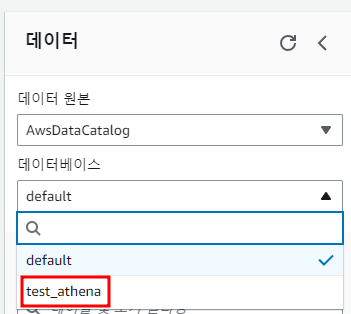
5. 테이블 정의
데이터베이스를 생성했으므로 이제 테이블을 생성한다. 데이터가 저장된 경로와 테이블 컬럼, 데이터 타입 등을 지정해주어야 한다. 쿼리 편집기를 통해 SQL로 생성할 수도 있지만 이 글에서는 콘솔을 통해 생성해 보도록 한다.
사용할 데이터는 s3://athena-examples-myregion/cloudfront/plaintext/ 에 저장된 예시 데이터이다.
테이블 및 보기 항목 옆에서 생성 > S3 버킷 데이터 버튼를 클릭한다.

테이블의 이름과 어느 데이터베이스에 테이블을 생성할지 지정한다. 이 글의 경우 4번에서 데이터베이스를 생성했으므로 기존 데이터베이스 선택 항목을 사용한다. 필요하다면 이 화면에서 새로 데이터베이스를 생성해도 된다.

데이터 세트 항목에는 데이터가 저장된 위치를 지정한다. 데이터 저장 경로는 /로 끝나야 한다.
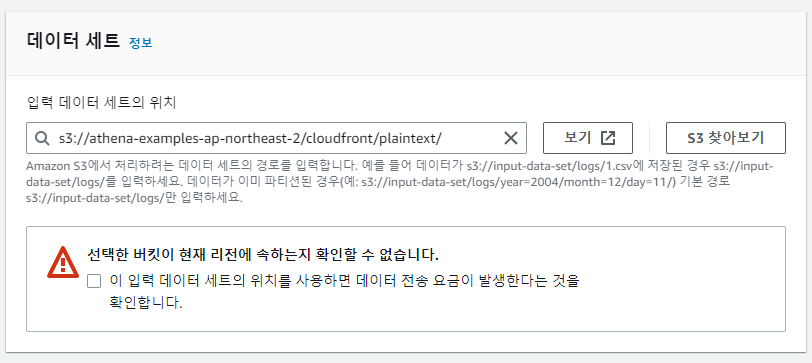
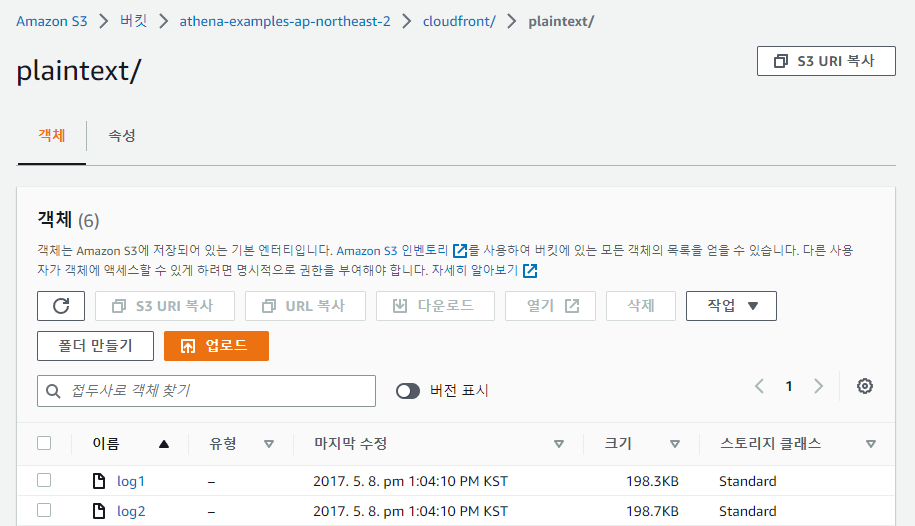
데이터 세트의 위치를 지정한 후 보기 버튼을 클릭하면 지정한 위치로 이동하여 데이터의 존재여부를 확인할 수 있다.
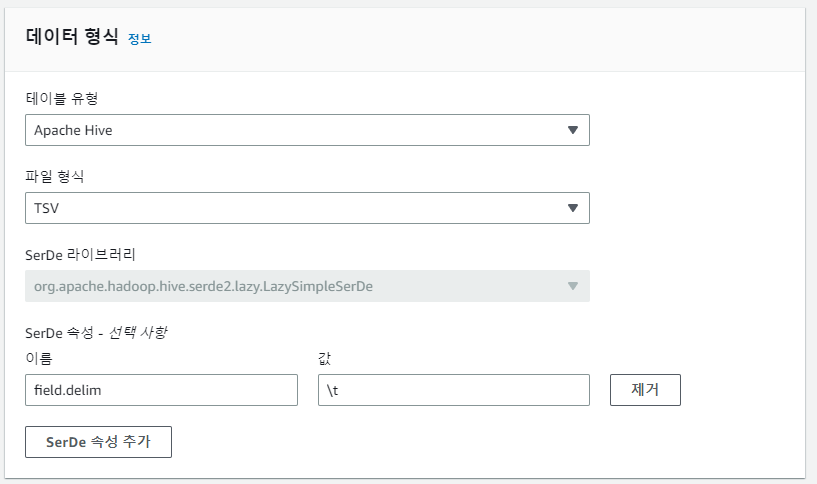
데이터 형식 항목에서는 테이블 유형과 파일 형식을 지정한다. 테이블 유형에 따라 다룰 수 있는 파일 형식이 정해져 있는데 TSV 파일의 경우 Apache Hive로 지정해주어야 했다.
테이블을 구성하는 컬럼의 이름과 데이터 타입을 지정한다.
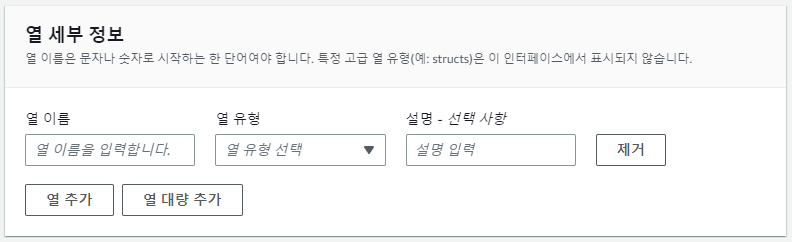
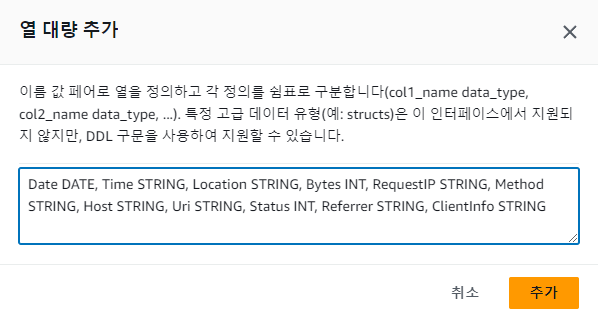
추가할 컬럼이 많다면 열 대량 추가 버튼을 클릭하여 col1_name data_type, col2_name data_type, ... 형식으로 컬럼 정보를 기재하여 추가할 수 있다.
Athena에서 지원하는 데이터 타입은 boolean, tinyint, smallint, int, bigint, double, float, decimal. char. varchar, string, date, timestamp. array, map이 있다.
이 외의 선택 사항인 작업을 넘어가면 생성할 테이블의 쿼리를 미리 확인할 수 있다.
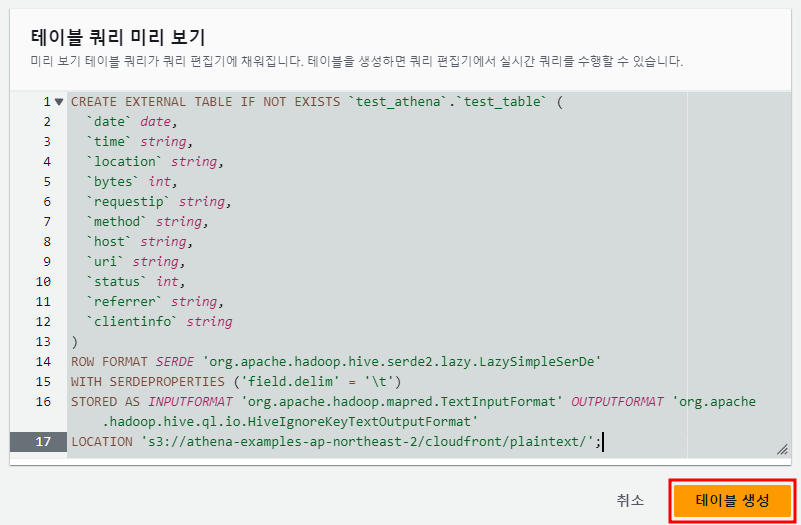
이상이 없다면 테이블 생성 버튼을 클릭한다. 클릭하면 자동으로 쿼리 편집기로 이동하며 테이블이 생성된다.
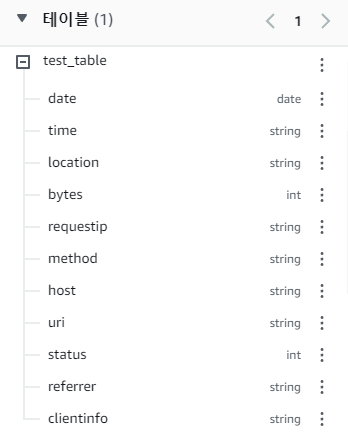
테이블 정보를 펼치면 컬럼 이름과 데이터 타입을 확인할 수 있다.
데이터 쿼리
데이터를 쿼리할 준비를 마쳤으므로 생성한 테이블을 대상으로 쿼리문을 실행해 본다.
Athena에서 테이블을 지정할 때는 <DB_NAME>.<TABLE_NAME> 형식으로 지정해야 한다.
SELECT *
FROM <db_name>.<table_name>;
-- 예시
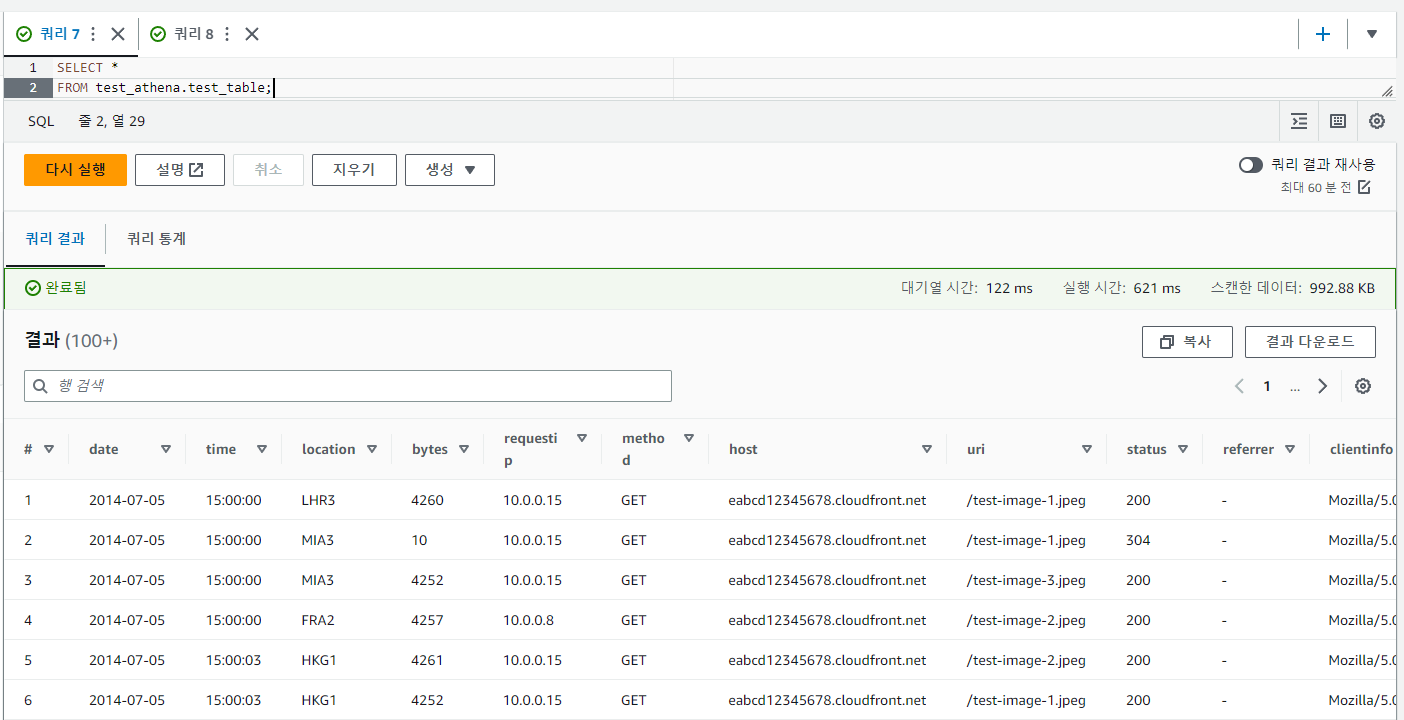
SELECT *
FROM test_athena.test_table;쿼리를 실행하면 정상적으로 결과가 출력된다.
참고 문서
[AWS] 📚 Athena 사용법 정리 (S3에 저장된 로그 쿼리하기)
https://jaemunbro.medium.com/aws-athena-presto-query-guide-886ce047d710
https://docs.aws.amazon.com/ko_kr/athena/latest/ug/getting-started.html